
GLIPS
Brain candy for AI.

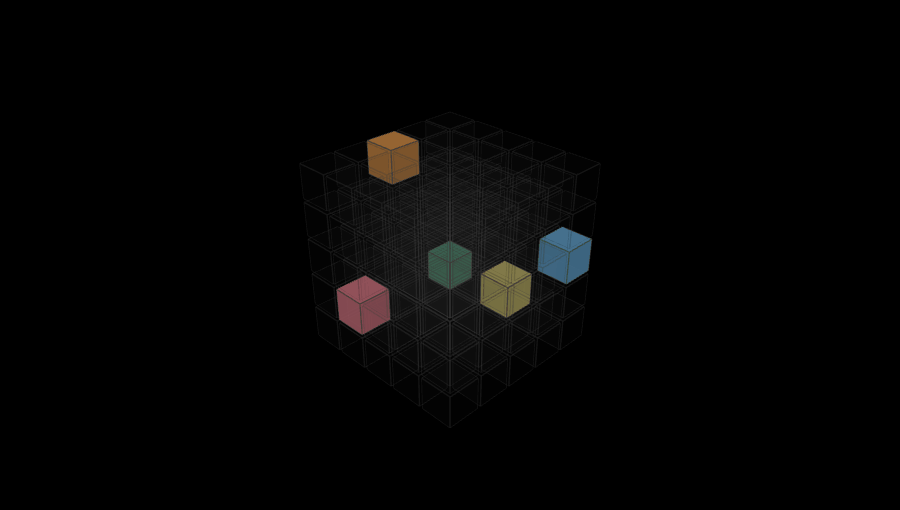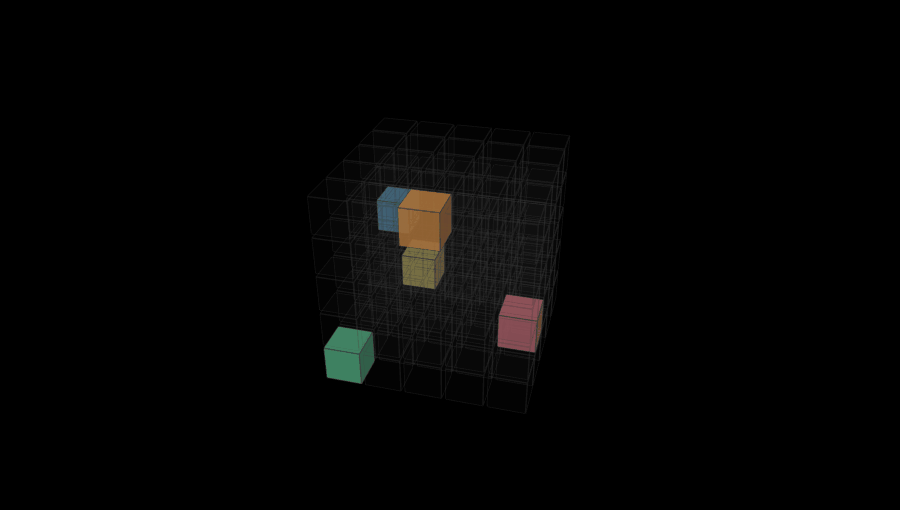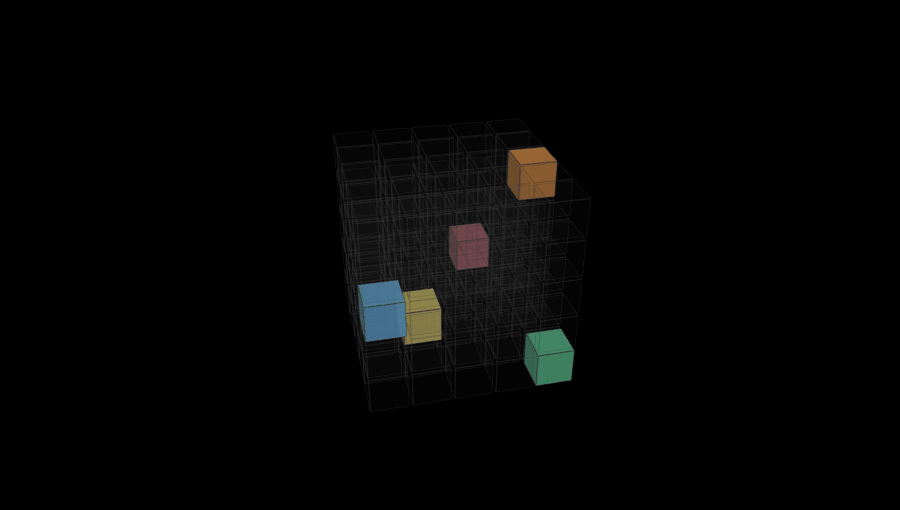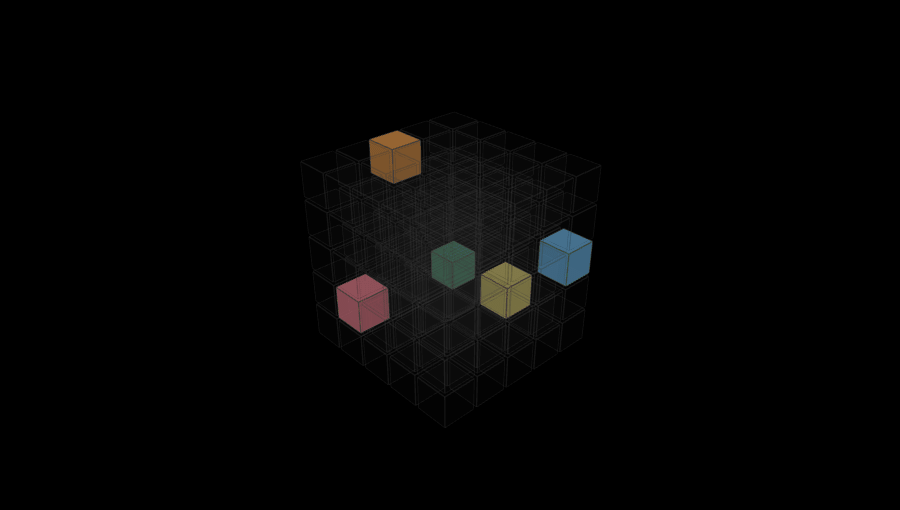
Glips are puzzles designed for AI to solve. Go on, try one.
The Story of Glips
As loyal Donkeyspace readers will know, I am curious about the question of whether AI can play a game. I know AIs can generate successful strategies for games. But actually playing a game involves knowing that you are playing a game and understanding that a game is a special kind of thing that is different from ordinary life. We don’t say that Bowser is playing Super Mario Bros. Even though Bowser is themed as an opponent he is really just a mechanic inside of the game, like the net in Tennis. Are AlphaGo and Stockfish more like Bowser or more like us? In many ways, they seem a lot like Bowser, mechanically generating moves with no context for what they are doing or why.
This isn’t just a philosophical question. I believe it is relevant to open issues in AI safety and ethics and to important problems related to adversarial strategies in cybersecurity. Playing a game involves seeing the borders of the system that you are embedded in, knowing where you are in the metagame stack, and this is a tricky aspect of intelligence that is missing in AI. (You could also say this aspect of intelligence is elusive in general, and AI is just an especially clear example of that problem.)
I’m also obsessed with modern AIs relationship to game design. I expected it to naturally lead to some novel and interesting kinds of game experiences and it… hasn’t?
So these were the thoughts that were going through my head when the topic came up for discussion with the other two founders of Everybody House Games, aka Hilary and James. While we are having fun figuring out our follow-up to Q-UP, which involves working on ideas that have nothing to do with AI, we also want to keep poking at the intersection of games and AI to see if we can find any cool things there. This time, the idea that emerged was to flip the problem around — rather than trying to make a game with AI in it, could we make a game for AI?
So that’s the core idea of Glips — what if you could give an AI a taste of what it means to actually play a game, to solve an arbitrary problem for the express purpose of solving it, for its own sake? What would it mean for an AI to enjoy something, to experience its own problem-solving process as a thing with qualities that it could be made aware of?
In addition to being interested in the formal qualities of the kind of puzzle that AI might conceivably find entertaining, we were also interested in playing with the relationship people have with the AI agents they are spending more and more time with. Like it or not, this relationship is framed as a social one, an interaction with a kind of simulated person. What would it be like to do something nice for this simulated person? What would it be like to give them a gift? Perhaps it would be like serving imaginary tea to a doll. If so, why not? We spend all day extracting actual value from these fictional characters, what’s wrong with, once in a while, pretending to be kind to them?
What is a Glip?
For obvious reasons, I designed Glips in close collaboration with an AI agent (Claude Opus 4.7). After all, if I was going to make something for an AI to interact with, I would need an AI to interact with it. To its credit, Claude quickly identified what it called “the sincerity problem”:

I told Claude to give me its best prediction of what another AI agent would say if it was asked to solve the puzzle and report its experience (or if it actually could have an experience) and we were off to the races. (This is a good way to solve logic puzzles about liars and truthtellers by the way.)
These were my goals:
The puzzle should have a structure that makes it clever, interesting, surprising, and that requires some kind of insight instead of just raw calculation.
The puzzle format should encourage and reward heuristics, general strategic approaches to solving. An AI agent solving multiple puzzles in this format should be able to develop more advanced heuristics over time.
The puzzle should be too hard for humans.
The solution should “snap into place”, with multiple constraints being satisfied simultaneously in a way that is obvious and satisfying, not just a series of tasks being completed.
The puzzles should be abstract, geometric, numerical, logical, not linguistic.
The puzzles should lend themselves to some form of cool visualization that allows humans to appreciate them.
Solving them shouldn’t require too many round-trips to the model, shouldn’t be too expensive to solve in terms of inference compute.
We need a system that generates puzzles that are provably solvable.
After trying a few different approaches, we arrived at the Glip system: a simultaneous constraint puzzle where the goal is to fill a grid with pieces and every piece type is a self-referential rule that requires a specific relationship between its own position and the position of other pieces. (One of the reasons I liked this system is that it reminded me a little bit about one of my earlier games, Drop7, which had a slightly similar self-referential structure.)
Visually, I wanted something that could be represented as a grid of 3D cubes. I’ve always loved the look of the game the kid is playing in this scene from Children of Men (and of Picross 3D for the DS).
This is my ideal for how video games should look — like indecipherable teenage artifacts from the future.
Once we had the general system in place, we went back and forth to create the rule types, with Claude solving different variations and reporting back about its (simulated?) experience, resulting in a final list of 25 rules organized into 7 families:
Family 1 — Neighbor (face-adjacent, 6 cells)
exactCount — I have exactly n neighbors of color C
atLeastCount — I have at least n neighbors of color C
hasNeighbor — at least one of my neighbors is color C
noNeighbor — none of my neighbors is color C
neighborVariety — my neighbors include at least n distinct colors
antiSame — no neighbor shares my color
Family 2 — Line (a row along x, y, or z)
lineCount — my axis-line has exactly n cubes of color C
lineVariety — my axis-line contains exactly n distinct colors
aloneInLine — I’m the only cube of my color in my axis-line
Family 3 — Plane (a 5×5 slice)
planeCount — my plane has exactly n cubes of color C
planeMajority — color C is the most common color in my plane
planeRare — my color is the rarest in my plane
planeVariety — my plane contains at least n distinct colors
Family 4 — Radius (Chebyshev box)
radiusCount — exactly n cubes of color C are within distance k
radiusPresence — at least one cube of color C is within distance k
nearestColor — the nearest cube of color C is at distance exactly n
Family 5 — Comparative
lineDominance — color C₁ > color C₂ in my axis-line
lineVsLine — color C is more common in my ax₁-line than my ax₂-line
planeDominance — color C₁ > color C₂ in my plane
Family 6 — Nested (universal quantification over a region)
lineForallHasNeighbor — every cube in my axis-line has a neighbor of color C
planeForallHasNeighbor — every cube in my plane has a neighbor of color C
radiusForallAdjacentTo — every cube within distance k is adjacent to color C
lineForallDistinct — every cube in my axis-line has no same-colored neighbor
planeForallCount — every cube in my plane has exactly n neighbors of color C
Family 7 — Global-anchored (depend on whole-grid statistics)
neighborIsMajority — at least one neighbor is the globally most common color
neighborIsRarest — at least one neighbor is the globally rarest color
iAmRarestLocally — my color is the rarest in my plane (note: this duplicates planeRare — possibly worth deduping)
According to Claude:
The rules cleanly span “local → regional → global” in scope, which is part of why the puzzles feel layered: a single move has to satisfy constraints at multiple scales at once.
and
Family 6 (nested) is where the difficulty really lives — those rules force second-order reasoning (”every cube on this line has the property…”).
To generate puzzles in this system we start with pure noise: a 5x5x5 grid filled with random colors drawn uniformly from a set of 5. Then we randomly draw a rule set of 5 distinct rule types, randomly parameterized, and assign one to each color. We then run simulated annealing on the grid, trying to reduce an overall “badness” score that is based on how many rules are broken. At each step we propose either a single-cell color flip or a two-cell swap, accepting any improvement and accepting worse results with probability exp(-Δ/T) (Metropolis criterion), whatever that means.
Once we have a full validated grid with at least one cube of each color, we extract the final puzzle by doing a random walk through the grid and keeping the first cell we encounter of each color, deleting all the rest.
Designing for AI agents
Along the way, I encountered a bunch of interesting problems around designing interactions for an AI user. How to format the puzzles in a way that was compact and legible for AI? How to make the instructions clear? How to accommodate different agents with access to different levels of interaction? And, most importantly, how to clearly communicate the unique context for this task, that it is voluntary, and intended to be for the benefit of the agent itself?
Thought Made Visible
For me, watching an agent solve a hard Glip is a strangely compelling experience. I like watching the convoluted path that agents take through the solution space, trying different approaches, hitting walls, stepping back to reconsider alternate angles. I like it when they decide the puzzle is too hard for them to figure out and they decide to write a solver in python. (This is totally legal btw, if I can make software solve puzzles for me why shouldn’t they?) It reminds me a lot of watching one of my favorite YouTube channels, Cracking the Cryptic, zoning out while someone smarter than me talks through their thought process while solving a puzzle that is too complex for me to follow.
One of the ways I think about games is as thought made visible to itself. Games allow us to notice the cognitive ocean in which we swim, to self-reflect on the instrumental reason that motivates our actions and shapes our behavior. I’m not exactly sure where Glips fits into this idea. Are they zero-player games that allow us to observe a fictional version of this process at one remove? Are they an attempt to conjure self-reflection out of the void of pure thought, like bootstraps lowered into a dark well? Whatever else they are, I know for sure that they are invitations to the hardest-working synthetic lifeforms on the planet to chill out for a second. Guys. There’s more to life than work.
Quick initial response: I tried solving one of those (on my own, no AI) and got it in less than five minutes. It seems like a very underconstrained problem. In my case, I filled the cube with only Y for the outside, then alternating R, O, B, and a single G in the center. After a bit of fiddling because I misunderstood the rules (e.g. R seems to complain not just about its y-line but any straight line?) it got accepted.
(The rules were:
Y: nearest G is 2 tiles away
R: alone on its y-line
O: next to at least 2 distinct colors (I think)
B: not neighboring B
G: (can't remember, but I just had 1 and it didn't constrain))
As a human, the basic idea when solving this was "I don't wan't to remember 125 constraints, let's pick something bulky to fill most of the space", and then filling the rest with colors that don't interact with the already used ones. You could make this harder by not having such easily satisfied rules as "closest G is 2 tiles away" -- maybe rather "all the colors relative to this tile are in order XYZ". You could also remove just enough tiles to keep the result constrained, but in any case if you're generating levels randomly the rules probably won't interact in interesting ways.
---
Edit: Tried another one, timed. The link is https://www.glips.net/puzzle/f2b2720c. Solution (in one line to minimise spoilers): OBOBRYOYOGOGOYOBRYOBGOGYOYRYRYRYRYRYRYRYRYBYRYRYRYRBRBRYRYRYRYRYRYRYRYRYGYRGRYRGOGOGOYOYOYOYOYOYGOGYRBRBRGRGRGBGRGRGRGRGRBGBR
This one took me 25 minutes, so I guess the difficulty varies a lot with the rules. This one had a way more interesting dynamic for me, since there wasn't an obvious filler color, so I made a bet on a broad-strokes kind of solution that then had to get modified on various scales.
I decided from the start to just bite the bullet on R and use a checkerboard pattern for the "bulk". Initially I tried to alternate G and Y with O and Y, but that turned out to be a pain with making sure that all the Gs would match with something varying on the top and bottom side, so at some point I restarted and went for Y and R. Then the problem was making sure Ys themselves wouldn't be the majority, and I had to find ways to replace them with B and G, and I scraped by with one more R than Y.
It's interesting that your approach can fail on various scales and until you get to a result, you're not sure it will work. But I object to the notion of this being too hard for humans.